이분탐색이란?
이분 탐색이란 정렬되어 있는 배열에서 특정 데이터를 찾기 위해 모든 데이터를 순차적으로 확인하는 대신 탐색 범위를 절반으로 줄여가며 찾는 탐색 방법이다.
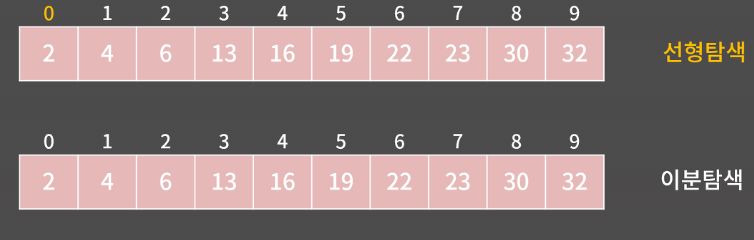
위의 선형탐색의 배열을 한번 살펴보게 된다면, 특정 데이터를 찾기 위해서 우리는 기존에 앞의 모든 데이터를 순차적으로 탐색 후 우리가 찾고자 하는 데이터를 얻는 순으로 진행된다.
예를 들어, 22라는 데이터를 찾는다고 가정할때, 0 -> 1 -> 2 -> .. -> 6값에 도달하였을때 데이터를 찾게 된다.
반면에 이분탐색은 정렬되어 있는 배열에서 특정 데이터를 찾기 위해 탐색 범위를 절반으로 줄여가며 찾는 탐색으로 진행된다. 선형탐색이 0(N)에 동작하고 이분탐색이 0(lgN)에 동작하기 때문에 N의 크기가 커질수록 프로그램의 실행 속도에 확연 차이를 보인다는 것을 알 수 있다.
Boj 1920번을 예제로 하여 풀이하도록 하겠다.
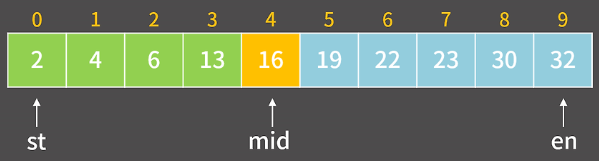
이분탐색을 하기 위해 st와 en 두 변수가 필요하다.
st는 배열의 시작, en는 배열의 끝으로 두고 정의를 한다.
이때, 찾고자하는 값이 22라고 가정을 할 때,
배열의 중점인 mid = (st + en) / 2라는 사실을 알 수 있다.
이때,, A[mid] = 16은 10보다 크기 때문에 st = mid + 1 로 변경할 수 있다.
다시, mid = (st + en) / 2 로 계산을 하고 en = en -1 을 할 수 있다.
이렇게 해서 한번 더 값을 구하려고 할 때에 st + 1을 해버리는 순간 우리가 찾고자하는 22의 값이 st - en 사이의 인덱스에 존재하지 않는다는 것을 찾을 수 있다. 이렇게 되는 순간, 우리가 찾고자 하는 target이 있다는 결과를 반환할 수 있다.
문제를 코드로 작성하여 풀이하겠다.
문제
N개의 정수 A[1], A[2], …, A[N]이 주어져 있을 때, 이 안에 X라는 정수가 존재하는지 알아내는 프로그램을 작성하시오.
입력
첫째 줄에 자연수 N(1 ≤ N ≤ 100,000)이 주어진다. 다음 줄에는 N개의 정수 A[1], A[2], …, A[N]이 주어진다. 다음 줄에는 M(1 ≤ M ≤ 100,000)이 주어진다. 다음 줄에는 M개의 수들이 주어지는데, 이 수들이 A안에 존재하는지 알아내면 된다. 모든 정수의 범위는 -231 보다 크거나 같고 231보다 작다.
출력
M개의 줄에 답을 출력한다. 존재하면 1을, 존재하지 않으면 0을 출력한다.
예제 입력 1
5
4 1 5 2 3
5
1 3 7 9 5
예제 출력 1
1
1
0
0
1
#include <iostream>
#include <algorithm>
using namespace std;
int a[100000];
int N;
int binarysearch(int target) //target 찾고자하는 값.
{
int st = 0;
int en = N-1;
while (st <= en)
{
int mid = (st + en) / 2;
if (a[mid] < target)
st = mid + 1;
else if (a[mid] > target)
en = mid - 1;
else
return 1;
}
return 0;
}
int main()
{
ios::sync_with_stdio;
cin.tie(0);
cin >> N;
for (int i = 0; i < N; i++) cin >> a[i];
sort(a, a + N); // 입력받은 순서대로 정렬
int m;
cin >> m;
while (m--)
{
int t;
cin >> t;
cout << binarysearch(t) << '\\n';
}
}


